
| Version 60 (modified by , 14 years ago) ( diff ) |
|---|
How to get started
First, you need an account. Please check the UsagePolicy if you are eligible. In order to get an account please register here.
A typical experiment requires the following three steps:
Reservations
As this is a wireless testbed, it is difficult to run multiple experiments without interference. Therefore, we currently only support one experiment at a time on the individual grid. In Orbit speak, a grid is a set of nodes together with the controlling console which can be used to run experiments. In the present setup, the testbed consists of a single large grid (main grid) with 400 nodes and an array of sandboxes i.e. "grids" with only 2 nodes and a console, which are development and test environments intended to reduce the time experimenters need on the main grid. Ideally, experimenters develop their software (application programs, routing protocols, measurement instrumentation, etc.) on off-site machines and then use the sandboxes for integration with the orbit environment and orbit software infrastructure. Once the experiment runs successfully in the sandbox environment, it can be moved to the main grid.

|
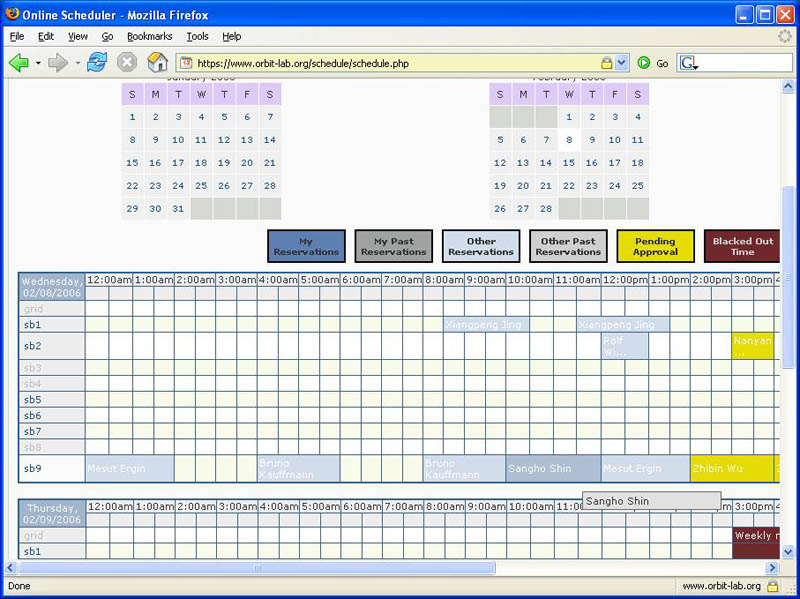
| Figure 1: Scheduler web page |
Reservations for Orbit resources (the main grid or any of the sandboxes) can be made on the ORBIT Schedule page. The scheduler main screen is illustrated in Figure 1.
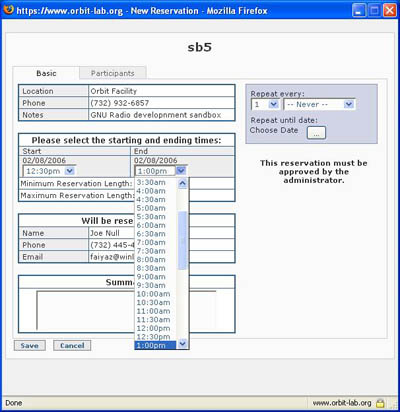
To reserve a resource, first navigate to the table for the day you wish to make the reservation on (please note that you can advance the calendar by using navigation links at the bottom of the page; also you cannot reserve a resource for a date/time that has passed or the one for which you don't have permission). Once you have located the table for the requested day, click on the time slot you want to use as a start time of your resource reservation. This will open the form showing the detail of the reservation. Currently slot duration is limited to 2 hours per request.


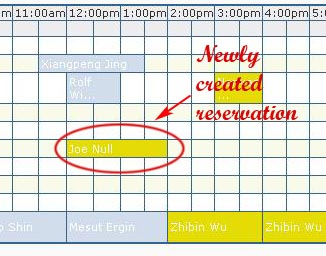
After saving the reservation, the pop-up windows is closed and main scheduler table is updated with the newly created reservation slot in yellow color indicating that it is in the "pending approval" state. Also, the email notification on the reservation is sent to your registered email address.
Reservations slots are approved by the scheduling service based on the two stage approval policy. Once it has been approved, the color for that slot will be changed to dark blue and approval email notification message will be sent to the requester and requester will be able to access the console of the resource whose reservation was just approved.
Conflicts
It is possible to ask for a particular slot even if other user already made a reservation for it. The procedure is the same as for requesting an empty slot except that the resulting color changes to red once there are multiple simultaneous (conflicting) reservations as shown in Figure 2.

|
| Figure 2: Scheduling Conflicts |
Reservation Approval Policies
Reservation approval process is based on a two stage algorithm. In the first (pre-approval) stage, scheduling requests received before noon will be pre-approved for the following day. For example, if it is Tuesday morning before noon, and you ask for 4 to 6 in the evening Wednesday, you will know for sure whether you have this time by 2 in the afternoon on Tuesday. Users are limited to two hours a day of pre-approved time on the main grid.
For the reservations that are made less than twelve hours in advance or for ones that are more than 2 hours a day, the slots will be automatically approved at the beginning of the slot (second or just-in-time approval stage).
Conflict Resolution
Conflicts will be resolved based on how much time you've already used over the last two weeks. Those who have used less time on the main grid in the last two weeks will be more likely to have their requests approved for the conflicting slots.
Due to complexity of the conflict resolution algorithm, please refrain from conflicting on slots that are less that 2 hours in the future since just-in-time approval process will not try to resolve conflicts.
Loading an Image
During your approved time slot, you will be able to ssh into the console of the respective grid. A console is a dedicated machine that allows access to all resources on that grid.
During your approved time slot, you can then log into the console corresponding to the following table using SSH:
| Name | Nodes | Console FQDN | Special Resources |
| Main grid | 400 | console.grid.orbit-lab.org | USRP2, USRP1, Blue too, Zigbee, etc… |
| Sandbox 1 | 2 | console.sb1.orbit-lab.org | None |
| Sandbox 2 | 2 | console.sb2.orbit-lab.org | None |
| Sandbox 3 | 2 | console.sb3.orbit-lab.org | USRP2 |
| Sandbox 4 | 9 | console.sb4.orbit-lab.org | RF isolated nodes + mixer |
| Sandbox 5 | 2 | console.sb5.orbit-lab.org | USRP1 |
| Sandbox 6 | 2 | console.sb6.orbit-lab.org | WinC2R |
| Sandbox 7 | 2 | console.sb7.orbit-lab.org | None |
| Sandbox 8 | 2 | console.sb8.orbit-lab.org | None |
| Sandbox 9 | 11 | console.sb9.orbit-lab.org | Netfpga + Openflow |
| Outdoor | Variable | console.outdoor.orbit-lab.org | Variable |
For example, to access the sandbox1,
yourhost>ssh username@console.sb1.orbit-lab.org
When you have successfully logged in, you can start an experiment using the Orbit Management Framework (OMF). First time users are highly encouraged to reserve time on a sandbox instead of the main grid, and start with the built-in Hello World experiment.
- Before we begin using the nodes, it's a good idea to check their status first. This is done with the omf stat command. This will typically produce a result like:
user@console.sb7:~$ omf stat INFO NodeHandler: OMF Experiment Controller 5.4 (git c005675) INFO NodeHandler: Slice ID: default_slice (default) INFO NodeHandler: Experiment ID: default_slice-2013-01-16t15.28.15-05.00 INFO NodeHandler: Message authentication is disabled INFO Experiment: load system:exp:stdlib INFO property.resetDelay: resetDelay = 230 (Fixnum) INFO property.resetTries: resetTries = 1 (Fixnum) INFO Experiment: load system:exp:eventlib INFO Experiment: load system:exp:stat INFO Topology: Loading topology ''. INFO property.nodes: nodes = "system:topo:all" (String) INFO property.summary: summary = false (FalseClass) INFO Topology: Loading topology 'system:topo:all'. Talking to the CMC service, please wait ----------------------------------------------- Domain: sb7.orbit-lab.org Node: node1-1.sb7.orbit-lab.org State: POWEROFF Node: node1-2.sb7.orbit-lab.org State: POWEROFF ----------------------------------------------- INFO EXPERIMENT_DONE: Event triggered. Starting the associated tasks. INFO NodeHandler: INFO NodeHandler: Shutting down experiment, please wait... INFO NodeHandler: INFO run: Experiment default_slice-2013-01-16t15.28.15-05.00 finished after 0:6
Individual nodes are identified by their fully qualified domain name (FQDN). This establishes their "coordinates" and the "domain" to which they belong. Nodes in different domains can NOT see each other.
- Node can be in 1 of 3 states:
POWEROFF Node is Available for use but turned off POWERON Node is Available and is on NOT REGISTERED Node is not Available for use
- It is recommended that the node be in the POWEROFF state prior to any experiment process. If the node is in the POWERON state you can use the omf tell command
to get the node into the off state.
username@console.domain:~$ omf tell -a offh -t TOPOLOGY
The TOPOLOGY can take on many forms, the simplest being a comma separated list of FQDN's. There are special predefined topologies like: all, system:topo:circle, … For more details see OMF documentation If the node is in the NOT REGISTERED state, you may need to wait for it to recover the POWEROFF state (it some times requires a few moments for the services to sync up). If the node never comes out of the NODE NOT AVAILABLE state please contact an administrator.
- Prior to the experiment, users need to install an image on the hard disks of the nodes. If you have not created a custom image use the default starting image:
baseline.ndz. This image is built on top of Ubuntu 12.04, and is pre-configured with the proper modules and start up scripts to take advantage of the rest of
the Orbit services / hardware. Loading an image is done with the omf load command.
username@console.domain:~$ omf load -t TOPOLOGY -i IMAGENAME
Where TOPOLOGY is the set of nodes you wish to image , and !IMAGENAME is the name of the image you with to load. The most common sandbox starting image command would look likeusername@console.domain:~$ omf load -t all -i baseline.ndz
which will load all the nodes of sandbox 1 (totaling 1) with the baseline image. An example run on sandbox 7 looks like:user@console.sb7:~$ omf load -t all -i baseline.ndz INFO NodeHandler: OMF Experiment Controller 5.4 (git c005675) INFO NodeHandler: Slice ID: pxe_slice INFO NodeHandler: Experiment ID: pxe_slice-2013-01-16t14.56.02-05.00 INFO NodeHandler: Message authentication is disabled INFO Experiment: load system:exp:stdlib INFO property.resetDelay: resetDelay = 230 (Fixnum) INFO property.resetTries: resetTries = 1 (Fixnum) INFO Experiment: load system:exp:eventlib INFO Experiment: load system:exp:imageNode INFO property.nodes: nodes = "system:topo:all" (String) INFO property.image: image = "baseline.ndz" (String) INFO property.domain: domain = "sb7.orbit-lab.org" (String) INFO property.outpath: outpath = "/tmp" (String) INFO property.outprefix: outprefix = "pxe_slice-2013-01-16t14.56.02-05.00" (String) INFO property.timeout: timeout = 800 (Fixnum) INFO property.resize: resize = nil (NilClass) INFO Topology: Loading topology 'system:topo:all'. INFO Experiment: Resetting resources INFO stdlib: Waiting for nodes (Up/Down/Total): 0/2/2 - (still down: node1-2.sb7.orbit-lab.org,node1-1.sb7.orbit-lab.org) [0 sec.] INFO stdlib: Waiting for nodes (Up/Down/Total): 0/2/2 - (still down: node1-2.sb7.orbit-lab.org,node1-1.sb7.orbit-lab.org) [10 sec.] INFO stdlib: Waiting for nodes (Up/Down/Total): 0/2/2 - (still down: node1-2.sb7.orbit-lab.org,node1-1.sb7.orbit-lab.org) [20 sec.] INFO stdlib: Waiting for nodes (Up/Down/Total): 0/2/2 - (still down: node1-2.sb7.orbit-lab.org,node1-1.sb7.orbit-lab.org) [30 sec.] INFO ALL_UP: Event triggered. Starting the associated tasks. INFO exp: Progress(0/0/2): 0/0/0 min(node1-2.sb7.orbit-lab.org)/avg/max (30) - Timeout: 760 sec. INFO exp: Progress(0/0/2): 10/10/10 min(node1-2.sb7.orbit-lab.org)/avg/max (30) - Timeout: 750 sec. INFO exp: Progress(0/0/2): 10/15/20 min(node1-1.sb7.orbit-lab.org)/avg/max (30) - Timeout: 740 sec. INFO exp: Progress(0/0/2): 20/25/30 min(node1-2.sb7.orbit-lab.org)/avg/max (30) - Timeout: 730 sec. INFO exp: Progress(0/0/2): 30/35/40 min(node1-1.sb7.orbit-lab.org)/avg/max (30) - Timeout: 720 sec. INFO exp: Progress(0/0/2): 40/40/40 min(node1-2.sb7.orbit-lab.org)/avg/max (30) - Timeout: 710 sec. INFO exp: Progress(0/0/2): 40/45/50 min(node1-1.sb7.orbit-lab.org)/avg/max (30) - Timeout: 700 sec. INFO exp: Progress(0/0/2): 50/55/60 min(node1-1.sb7.orbit-lab.org)/avg/max (30) - Timeout: 690 sec. INFO exp: Progress(0/0/2): 60/65/70 min(node1-1.sb7.orbit-lab.org)/avg/max (30) - Timeout: 680 sec. INFO exp: Progress(0/0/2): 60/65/70 min(node1-1.sb7.orbit-lab.org)/avg/max (30) - Timeout: 670 sec. INFO exp: Progress(0/0/2): 70/75/80 min(node1-2.sb7.orbit-lab.org)/avg/max (30) - Timeout: 660 sec. INFO exp: Progress(0/0/2): 90/90/90 min(node1-2.sb7.orbit-lab.org)/avg/max (30) - Timeout: 650 sec. INFO exp: Progress(1/0/2): 90/95/100 min(node1-1.sb7.orbit-lab.org)/avg/max (30) - Timeout: 640 sec. INFO exp: Progress(2/0/2): 100/100/100 min()/avg/max (30) - Timeout: 630 sec. INFO exp: ----------------------------- INFO exp: Imaging Process Done INFO exp: 2 nodes successfully imaged - Topology saved in '/tmp/pxe_slice-2013-01-16t14.56.02-05.00-topo-success.rb' INFO exp: ----------------------------- INFO EXPERIMENT_DONE: Event triggered. Starting the associated tasks. INFO NodeHandler: INFO NodeHandler: Shutting down experiment, please wait... INFO NodeHandler: INFO NodeHandler: Shutdown flag is set - Turning Off the resources INFO run: Experiment pxe_slice-2013-01-16t14.56.02-05.00 finished after 3:13
- The imageing process will turn the nodes back off after completing imageing. At this point the nodes disks are imaged with the basline image
and need to be turned back on before proceeding.
username@console.domain:~$ omf tell -a on -t all
Give the nodes a couple of minutes to turn on / boot, then check their status with omf stat.
Where to go from here
If you are still unsure what Orbit is, please read the FAQ and the Tutorial, otherwise go ahead and register.
Attachments (5)
- Schedule-howto3.jpg (128.8 KB ) - added by 14 years ago.
- Schedule-howto4.jpg (56.7 KB ) - added by 14 years ago.
- Schedule-howto5.jpg (49.3 KB ) - added by 14 years ago.
- Schedule-HowTo6.jpg (66.6 KB ) - added by 14 years ago.
-
Result.png
(284.5 KB
) - added by 11 years ago.
Demo result pae
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip