
| Version 61 (modified by , 13 years ago) ( diff ) |
|---|
Multiple Controllers (And making them cooperate).
This page documents the process of designing a multi-controller OpenFlow architecture where the controllers actively collaborate to emulate a network stack for experiments.
This "logging" method is based on a relatively effective method developed during a GSoC 2012 project.
These notes will eventually be turned into documentation suitable for human eyes.
Quick Links.
Overview
Logistics
Subpages - extra notes related to this page
Logs - records of work
week1 week7 week13 week24 week32 week2 week8 week15 week25 week33 week3 week9 week17 week28 week4 week10 week19 week29 week5 week11 week20 week30 week6 week12 week23 week31
Overview.
The basic architecture for an OpenFlow network is a client - server (switch - controller) model involving a single controller and one or more switches. Networks can host multiple controllers. FlowVisor virtualizes a single network into slices so that it can be shared amongst various controllers, and the newest OpenFlow standard (v1.3.0) defines equal, master and slave controllers to coexist as part of a redundancy scheme in what would be a single slice. A multi-controller scheme that isn't really explored yet is one where each controller has a different function, and cooperate.
Cooperation is a fairly complex task, for several reasons:
- There must be a communication scheme so that the controllers can cooperate
- A single protocol suite can be divided amongst controllers in various ways
- The information being communicated between controllers changes with protocol suite and division of tasks
Developing a general solution to this problem is difficult, so focus will be narrowed down to a more specific task of producing a cooperative multi-controller framework for running a topology configuration service split into a global and local component, and an experimental routing protocol with ID resolution.
Logistics
Work Setup
The Mininet SDN prototyping tool will be used for testing and debugging implementations. The implementation will be based on modified versions of OpenFlow Hub's Floodlight controller.
Proof-of-concept experiments for evaluating the architecture will be run on ORBIT sandboxes.
Timeline
An approximate 3.5 months (14 weeks) is allotted for design, implementation, and evaluation. the ideal split of time is the following:
- 3-5 weeks: architecture layout, topology control, context framework
- 3-4 weeks (end of: week 6-9): integrating routing/resolution
- 3-4 weeks (end of: week 9-13): evaluation
- remainder (end of: week 14): documentation
This schedule is a general outline and is used as a guideline; the actual work-flow will inevitably change.
Subpages
- A Thought Exercise: A "prologue" (ASCII text) page on thinking about multi-controller architecture design to get back up to speed after a hiatus.
- Distributed controllers: A list of distributed controllers, with breif descriptions of each
- Floodlight Internals: A summary of Floodlight internals.
- OpenFlow Vendor message HOWTO: A rundown on using and creating OpenFlow Vendor messages in Floodlight.
Logging.
(9/5):
keywords: hierarchy, collaboration.
We are set on having a weekly meeting, starting with this one.
The consensus is that a general architecture is beyond the scope of what's possible within the available timespan. The design is simplified to a narrower case:
- controllable topology (mobility as a change in topology). A global controller with a view of the network initially configures the topology. Lower (local) controllers can detect topology change and either update the global view or handle it themselves.
- controller per service and switch
- hierarchical relation between controllers. with less active protocols higher up
- information distribution mechanism between controllers, namely service location (topology). Certain controllers may add context to port, depending on what is attached to them. The topology controller must be able to convey the location of the service to that controller. Possibly an request/reply/subscription based scheme, the subscription being useful for events (topology change).
The course of action now is to look for the following:
- Basic topology control
- Test case of mobility/handoff/flow switching (OpenRoads)
- Mechanisms that can be used to exchange service/event information
(9/7):
Added a good amount of content to Floodlight Internals.
We need to define inter-controller communication. At the basic level controllers can communicate by passing OpenFlow messages amongst themselves. This is like a not-so-transparent, upside-down version of FlowVisor.
(9/9):
The primary steps of concern seem to be the following:
- create a controller that can connect to other controllers
- pass messages between them (get one to send something to other)
- intercept and use messages (get recipient to act on message)
- make this symmetric (for request/reply/update)
somewhere along the way, we need to devise a service type message/servicetype codes that can be meaningful. For now it is probably a good sanity test to get two controllers to connect to each other, akin to what FlowVisor does.
The easiest approach may be to create a module that opens up its own connection, exporting a "switch service" that handshakes with a remote controller.
(9/10):
Beginning of creating a basis for controllers that can be connected together. Tentatively calling the controllers that are going to be part of the hierarchy "units", as in, "units of control".
This involved taking OFChannelHandler and creating something similar to it, for connections from (down-links to) other controllers. At first represented connections from units as their own implementations, then figured this was problematic if the packets from the controllers are to be handled by the modules. This means it makes sense to represent the connections from other controllers as OFSwitchImpls.
Two new mock-OFProtocol types were created for inter-unit messaging.
- OFUnitServiceRequest: request for list of services from unit
- OFUnitServiceReply: relevant service information
The service reply will probably communicate a service type (topology, network storage, etc.) and a location to find it, such as port on a datapath where a NAS is located (if network storage). This is basically a way for the network to advertise location of services to topology-aware elements, as opposed to a server attached to a network doing the adverts for hosts.
(9/11)
Some work was done to develop a general architecture of a single controller, tentatively named a "Unit". A unit can handle both switch connections as well as controller connections. Controller connections come in two flavors:
- upstream - outgoing connects to a remote one, used to pass a message to higher tiers
- downstream - incoming connections from a remote one, used to return a result to the lower tiers after processing
Incoming connections are made to a "known" port. Two controllers connected to each-other via both are adjacent.
End of week1 :Back to Logs.
(9/12)
Several points were discussed.
- Same versus different channels for switches and controllers. Same channels for both implies a need for a strictly defined protocol between controllers, and a more sophisticated upstream message handler for the channel. Different channels allows the system to be more modular, and removes the need to develop the "smart" handler that may become cumbersome to debug and develop overall.
- Vertical versus horizontal inter-controller channels. Vertical channels are connections between controllers in different layers of the hierarchy, whereas horizontal channels are between those in the same layer. Horizontal channels may contain both OpenFlow control and derived messages. Vertical messages may not conform to OpenFlow, with the exception of the vertical channel between the first level controllers and switches (the traditional OF channel).
- Nature of non-conforming messages. The Vertical messages are "domain-specific", that is, only conform to rules that are agreed upon between adjacent layers. Therefore, some translation must occur if a message is to pass across several layers. Alternately, one message type may be interpreted differently across different tiers. An Example is one layer using a VLAN tag as a normal tag, and another, a session ID.
- Interdomain handoffs. The network may be a mix of IP and non-IP networks, governed by controllers not necessarily able to communicate - each should be able to operate in their local scope, facilitating the translation of outgoing messages so that it may be handled properly by the IP portions of the internetwork.
- Use case. A small setup of three switches, two hosts (one moving), and two tiers of controllers. The first tier may be a simple forwarding unit, and the second dictates a higher (protocol) layer logic - to keep it simple, authentication. The logical layout between the two tiers changes behaviors of the tiers:
- Tier two connects to just one tier one controller: the connection point must communicate the higher-tier's commands to others in its tier.
- Tier two connects to all tier one controllers: tier two in this case is a global 'overseer' that can actively coordinate, in this case, a handoff where permitted.
(9/13)
A second channel handler was added for inter-controller communication. This involves an addition of:
- a slightly modified ChannelPipelineFactory for the new channel pipeline (the logical stack of handlers that a message received on the channel will be processed by)
- a new ChannelHandler for the socket,
UnitChannelHandler, to the controller class - a new server-side channel bootstrapping object for this port (6644, "controllerPort") to the controller class
This page was used as a reference.
End of week2 :Back to Logs.
(9/20)
A topology file/parser were added. The file is a .json list of upstream and peer controller units (nickname:host:port triplet). This list is used to instantiate client-side connections to the neighbors.
The essential difference (as of not) between an upstream and peer unit are whether the client connection goes one way or both. Several ways to identify the origin of the message comes to mind:
- keep the original lists of neighbors, and find relation by lookup per message
- identify based on which message handler object receives message. The object:
- is identified as down, up, or peer (relation)
- manages outgoing connections to upstream or peer
- raw classification:
- if received on 6644 and no client connection to originator exists, it is from downstream
- if received on 6644 and a client connection to originator exists, it is from a peer
- if received on a high-number port and originator does not connect to 6644, it is from upstream
(9/21)
Realizing that the lack of understanding of the Netty libraries was becoming a severe hindrance, we inspect a few documents to get up-to-speed:
- Netty Channel handlers: http://www.znetdevelopment.com/blogs/2009/04/21/netty-using-handlers/
- Official Netty getting-started docs: http://docs.jboss.org/netty/3.1/guide/html/start.html
With the new resources at hand, we re-document the modifications done to the main Floodlight event handler (Controller.java) in order to intercept and respond to messages from both switches and controller units.
- The "server-side" channels. A control unit expects two types of incoming connections, 1) from switches, and 2) from other units (peer and downstream). These two are identified by default TCP port values of 6633 and 6644, respectively. The switch channel is handles using OFChannelHandler, which implements the classic OpenFlow handshake. The unit channel, which we add as the UnitChannelHandler to our Controller.java derivative class (UnitController.java), deals with the inter-unit handshake, which uses a modified version of OpenFlow. Both are initialized and added to the same ChannelGroup when the UnitController run() method is called.
- client-side channels. A controller unit with upstream or peer units will connect to other units as clients. Each client connection is handled by a UnitConnector, which attempts to connect to each remote socket specified in a topology file located, by default, under resources/ . Each entry describing a unit has the following form:
{
"name":"unit_name",
"host":"localhost",
"port": 6644
}
This can of course be easily changed, along with its parser (UnitConfigUtil.java) and structure holding the information for each entry (UnitPair.java). This file specifies peer and upstream units in separate lists, in order to facilitate the differentiation between the two kinds of server units. We define a unit that accepts connection to be a server unit, and ones connecting, client units. A separate channel handler is supplied for this connections.
However, it appears that all three channels use similar-enough channel pipelines, whose only differences lie in which handler is being used; therefore some work to be done in the future include a consolidation of the three PipelineFactories.
End of week3 :Back to Logs.
(9/26)
Things seem to be headed towards architectural experimentation. Three things to investigate:
- Radio Resource Management (RRM) : incorporate advertisements somehow, for between controllers
- Authentication : A entity that allows/denies a host to tx/rx on a network. This combined with forwarding elements provide a base foundation for collaborative multi-controller networks.
- Discovery : Controllers discover and establish links with, other controllers within the control plane, sans explicit configuration, like DHCP.
The first two are test cases to add credibility to a architecture like this one. In any case, the syntax for service/capabilities adverts must be defined.
The to-do'd for now:
- look up RRM.
- investigate process of host authentication.
- find examples of existing distributed controllers.
(9/29)
A quick survey for distributed controllers brought up several examples:
- Onix: A Distributed SDN control platform, which synchronizes controllers with a Network Information Base (NIB), which stores network state. Relies on a DHT + local storage. Oriented towards reliability, scalability, stability, and generalization.
- HyperFlow: A NOX application that allows multiple controllers to coordinate by subscribing to each other and distributing events that change controller state. Relies on WheelFS, a FUSE-based distributed filesystem.
- Helios: A distributed controller by NEC. Cannot find a white-paper for this one.
HyperFlow is what this (attempted) controller seems to resemble the most. However, the point to make is that this controller should not be just another implementation of one of these controllers, or their characteristics. The model for the currently existing distributed controller seems to assume that of multiple controllers that all run the same application, and to allow that one application to scale. This contrasts from the distribution of functions across multiple controllers e.g. having each controller run a different application to "vertically" distribute the load (Vertical - splitting of a network stack into several pieces as opposed to the duplication of the same stack across multiple controllers).
End of week4 :Back to Logs.
(10/4)
Seeing that the client-side channel implementation was not working as intended, a revision that can hopefully be worked back into the source was made.
As for the documentation aspect, several use cases for a multi-controller architecture that distributes tasks based on application (protocol) need to be devised. Some points made during discussion:
- Many networks contain various services that belong in separate "layers", which are maintained and configured by different groups, and may even reside on different devices.
- Viewing an analogy of a microkernel, where the various aspects of the kernel (w/r/t a monolithic architecture) are separated into processes that pass messages amongst themselves — various controllers may serve different protocols that make up a network stack. Not commenting on the performance of the microkernel architecture, but more so on its existence.
In terms of multi-controller networks, there are other cases that should be identified:
- OpenFlow 1.3 Roles: these are redundancy entities, with protocol-standardized messages to facilitate handoffs of switch control between controllers. The setup involves multiple connections originating from a single switch. The switch also plays a part in managing controller roles (e.g. must support this bit of the protocol). This is intended to provide a standardized interface, so it is not an implementation; Controllers must implement what these roles imply.
- Slices: these are designed to keep controllers that conflict with each other in separate pools of network resource, allowing each to exist as if they are the only controllers in the network. This effect is achieved thanks to a proxy, not collaboration between the controllers.
(10/5)
A test implementation of the switch-side handshake was added to the codebase, in a separate package net.floodlightcontroller.core.misc. This is a client-side ChannelHandler/PipelineFactory that generates switch-side handshake reply messages and ECHO_REPLIES to keepalive pings once it completes the handshake. This will be used as a base for the controller's client components.
Noting initialization, the handler's channel is set manually during client startup:
/*In client class*/
OFClientPipelineFactory cfact = new OFClientPipelineFactory(null);
final ClientBootstrap cb = createClientBootStrap();
cb.setPipelineFactory(cfact);
InetSocketAddress csa = new InetSocketAddress(this.remote, this.port);
ChannelFuture future = cb.connect(csa);
Channel channel = future.getChannel();
cfact.setHandlerChannel(channel);
This can probably be avoided if the handler is implemented as an inner class to the client class that fires up the channel, as in Controller.java.
(10/8)
With the base foundations mostly built, it seems to be a good time to document some of the components.
Component classes:
- ControlModuleProvider : the module that provides the controller class, based on FloodlightProvider.java
- ControlModule : the main controller class, subclass of Controller.java. Handles incoming connections from control plane and regular OpenFlow channels.
- ControlClient : the control plane client side event handler, one instantiated per outgoing connection.
- UnitConfUtil : Memoryless storage for topology and various other controller-related configurations.
- OFControlImpl : representation class for an incoming/outgoing connection to another controller, subclass to OFSwitchImpl.
Configuration files
- topology.json : stores topology information, e.g. neighbor controller information.
- cmod.properties : stores Floodlight module configurations for all loaded and active service-providing modules.
(10/11)
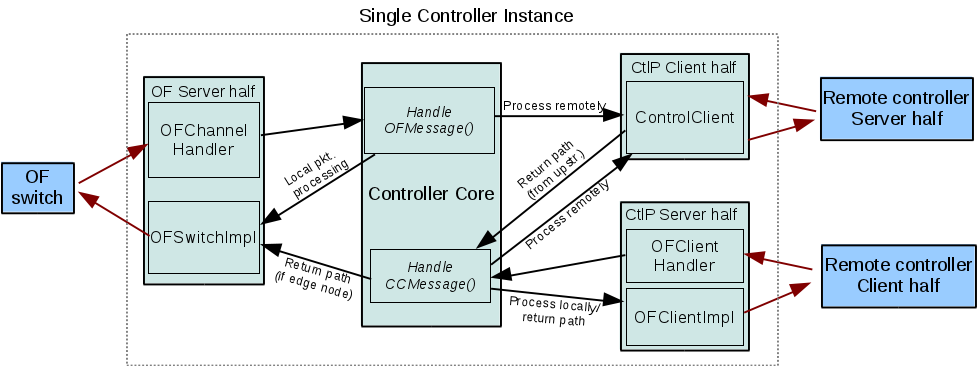
Some time was spent getting a better sense of the software architecture. The most recent organization looks like below:

This image attempts to summarize the required communication channels and message processing chain:
- Channels - OpenFlow (between switches and a controller), client/server connections between controllers on the control plane
- Message processing - local data processing, escalation/forwarding, and return path
In a sense, the main controller class is an implementation of a rudimentary kernel.
- Some more discussion on use case was had, in the context of different management domains with multiple controllers owned by separate groups, but on the same network. In the traditional network setup, each group would have to actively collaborate in order to prevent controllers from trampling each others' policies. For example, a central controller orchestrator, when allowing a user to administrate the network, would only permit the user to configure their own controller. The orchestrator would have to "know" which users can access which controller, and how that controller may influence the network.
End of week5 :Back to Logs.
(10/16)
The process chain was fleshed out further.
- remote connections appear like modules that subscribe to the events that they need for their service. For example, the authenticator would listen for any new device connections and departures, and not let packet_ins from the device to pass through further down the OFMessage chain if the host is not allowed (or inject drop messages for the denied host).
- since modules cannot be dynamically added, and we don't necessarily know how many connections will come in, the modules that squirrel events to other controllers will also accept arbitrary numbers of connections, and keep track of the mapping between message and channels.
(10/19)
- Added parser for controller service descriptions/requirements to the topology file. The configs for the controller are parsed, then pushed out as part of the service info exchange that controllers do with each other when establishing a connection. The aim is to be able to describe services in terms of the resources that it needs. The resources are in the form of events that the controller is capable of detecting and dispatching (messages, switches, and hosts/devices).
(10/20)
Preliminary decision to use Vendor extensions of OpenFlow specs for inter-controller service messaging, at least for controllers to propagate information about the services that they export, and what event information they require to properly run the service.
The base of a vendor message includes an integer to specify the data type, which allows one to use one "vendor ID" with many message types.
End of week6 :Back to Logs.
(10/24)
Some terms to keep things organized:
- Control plane : the collection of communication channels just visible to the controllers. Assumed to be isolated from the data plane, in which the switches and network hosts reside.
- network event : a message that notifies a controller of network state change, e.g. a switch joining the network, or a new OpenFlow message.
- Control entity : a SDN controller. May or may not be connected to switches but nevertheless capable of influencing network state by processing OpenFlow messages or its derivatives.
- Control plane server : a control entity that exports services to other controllers, and may subscribe to other controllers for network events. Also called "subscribers".
- Control plane client : a control entity that relays network events to control entities interested in them.
A server is configured with the information required to advertise its services and subscriptions. A single controller can also be both client and server.
Three unique control messages were defined using OF Vendor messages:
- OFExportsRequest : sent by a control plane client when initially connecting to a control plane server. Akin to an OFFeatureRequest.
- OFExportsReply : sent in response to a OFExportsRequest. Contains the names of the services exported by the server, and the events that it would like to subscribe to.
- OFExportsUpdate : sent by a server to its clients, when it receives (as a client) any new OFExportsReply messages from its servers.
The Reply and Update messages convey subscriptions as one of three categories:
- Device : network host related events such as a host join, departure, or address/VLAN change.
- Switch : OpenFlow switch joins and leaves.
- Message : OpenFlow messages distinguished by message type.
This reflects the event types that Floodlight recognizes by default, is well-defined, and is probably comprehensive enough to convey a very wide range of network events. The aim here is to define subscriptions as a combination of events from these event categories.
To keep things simple, of the Message category of events, focus will be placed on the Packet_In type (0x10), which is practically a catch-all for network host related messages. If more fine-tuned filtering is requires, a OFMatch structure may probably be used to describe the constraints on the types of Packet_Ins a subscriber may wish to hear about.
End of week7 :Back to Logs.
(11/2)
Concept work for the module front end to remote connections:
1.3 types of message processing chain behaviors, according to application type at remote end.
- Proxy : messages cannot be passed down chain until the remote module has processed things, and returned a decision. This includes firewalls and authentication.
- Concurrent : messages being processed by the remote module can also be processed by the others down the chain even while it is being remotely processed.
- Both : some modules may be required to wait for the results of the remote module, while others may work concurrently.
In terms of communicating the specific type, there can be a field that specifies preferred processing options in the ExportsReply messages.
2.Implementation wise, static modules makes dynamic connection additions difficult. In dynamic controllers, a module-per-connection may be added as connections are introduced, so tacking this problem is not considered to be a topic of interest. (However, it has to be done)
3.Flow entry merging is a nontrivial topic that is not covered due to its extensiveness. Once a flow entry is added, it is assumed to:
- aside from removal, never be modified
- not conflict with any others.
(11/3)
Process chain alterations based on request should be done at a per-event-category basis. The rationale comes from a few points, such as the how Floodlight processes events categorically, in separate modules, and not every event that may be subscribed to by one controller necessarily should be treated in the same manner. An example of this is for the authenticator, which subscribes to packet_Ins and new_device events; while packet_ins from a blacklisted host must not be processed by any other module capable of causing denied host traffic to be forwarded, new_device messages can be passed to other modules with little risk.
Several concerns are still up in the air, some of which may alter how sensible the above statement is:
- stub module(s) - one for each event category versus one for all categories. Former makes each simpler, but probably requires more context passing, while the latter makes shared data easier to manage but the module itself more complicated e.g. makes a second level scheduler necessary.
- multiple remote controllers with conflicting requests - For the same event. Strongly implies diversion should /not/ drop a event after it passes through one.
For starters, the most basic structure would be a diverting module(work on one at a time, the default dispatcher behavior)
End of week8 :Back to Logs.
(11/8)
The current state of the implementation is as follows:
- central configuration file for the advertisements sent by the controller
- single remote dispatch module that registers as a listener for devices, switches, and messages
- Vendor message-based control plane communication
Vendor message contents may be classified into initialization messages and service messages. The former are messages exchanged during an initial handshake between controllers, and the latter are messages used during normal operation e.g. for event messaging and returning processed results. In the interest of time, the controller-specific event contexts will probably be used for this purpose, as it can be used to directly manipulate the behavior of various modules. In the ideal case, a more general messaging format should work.
(11/15)
More work on integrating the connection registration system for the remote dispatcher module:
- The dispatch queue holds all registered connections, sorted by event category, and then events. This allows for lookup using the event category fired by the controller, so we don't need to do extra work to begin pulling up a list of potential event recipients.
- The dispatch queue is manipulated by the remote dispatch module, but is globally accessible through the controller class.
- The client-side connections may not always connect to the remote controller in one shot - therefore we add a crude wait-and-retry mechanism to the client handler.
- The client connections are dispatched from the remote dispatch module. This prevents some timing issues by guaranteeing that the dispatch module has started up before clients attempt to register with it.
End of week9 :Back to Logs.
(11/16)
The framework is probably developed to the point where it is good to test multiple instances against each other. There are several ways to do this, but, when working on a single machine, we need to have each instance read in a separate configuration file. A preliminary test setup involves a directory of configuration files, and a script to launch controller instances using the appropriate configuration files and stop them as necessary.
Discussions regarding benchmarks: A series of basic benchmarks are to be done. One of the most fundamental would be the overhead required for a flow insertion. Comparison with other platforms would come later, once this fundamental bottleneck is understood.
Future works: It is good to speculate on what can be made of this platform, given that it is a feasible one; One improvement to consider would be discovery-based startups, where the controllers do not need to be instructed who their neighbors are. This implies that advertisements are used to announce capabilities, and clients decide which services they require and choose based on the advertisements they hear on the wire. Connections can switch to dedicated stream once controllers choose their services.
(11/20)
XID translation, comparison to FlowVisor, and why it has a "better design", in terms of traditional distributed control planes.
XID translation is used as a way to map the incoming message's XID to a source and destination. This allows a message that has departed from one controller, and a response message, to retain the same XID to make it easy to track the origin of the original message. FlowVisor uses this technique to track the origin slice of messages. Our case is a bit convoluted for the following reasons:
- The origin switch/client of a message is only known to the dispatch module, which receives all messages and routes them to the appropriate destination server. This means that we are not able to keep track of the switch/client generating the event.
- XIDs are modified by the controller. Therefore, tracking sessions by the XID of the switch/client is impossible, unless we change the controller's behavior, possibly breaking protocol.
FlowVisor takes this into account through its architecture; The Classifiers, representing each switch, are coupled to each slice that the respective switches are part of. This allows all return path packets to pass through the classifier from which it originated, allowing the determination of the source "for free". This only leaves determination of the correct destination (e.g. slice) up in the air, and this is solved by the use of XID translation based on the messages originating from the slices.
Adopting this architecture may make things "easier", if possible. This requires several changes:
- A DStreamImpl that tracks all upstream destinations (UStreamImpl instances)
- A UStreamImple instance per DStreamImpl
- separate channel per instance of USTreamImpl - making for DStreamImpl-number of connections seen by the remote server.
However, this makes the network transparently visible to the higher-tier controller, which, in our case, is not the virtualized controller as with FlowVisor, but a higher-layer application. If virtualization /was/ the higher-layer application, it makes sense to make the network visible to the controller above, but for any plain application, hardware details (e.g. the network) should be something left to the low-lying logic (the lower-tier controllers). It would take some thinking before we modify this controller to make it more "FlowVisor-like".
End of week10 :Back to Logs.
(11/27)
IAB project report writeups. Implementation is on hold for now.
(11/29)
Some concepts for message handling by the remote dispatcher.
- SPLIT, DIVERT - the two types of operations that a new event can initially be handled with. Specified by the server side.
- BYPASS - allow skip of further processing by the remote dispatcher. That is, pretend that it doesn't exist and let the process chain process it like usual.
Return types:
- OFMessage : to be sent immediately down return path. Incoming event that produces these are never BYPASSed so they always hit the dispatcher, or remote controller's process chain.
- FloodlightContext : to be added to the context of the initial event, meaning the initial process chain must be preserved until the service returns.
- BYPASS : add event associated with a device to the bypass list. Incoming event producing this is a device or switch. Packet_ins associated with a device being evaluated are sent up, and returned to be replayed through the process chain with its context, which must be preserved.
For bypass, device identity is specified by MAC for now, which we assume doesn't change. The important part is that there is some unique identifier that can be used to specify a device. We also assume that each Packet_in is not sensitive to the handling of others, so they do not have to be processed in the order that they arrive. This is a simplifying assumption for the replay aspect of the bypass. Bypass is on a per-server basis, since some servers may still want the event even if another forgoes it.
(12/1)
Mostly garbled self-notes.
- "context-switching" - would be ideal for running a packet through a process chain after a delay. this involves saving the FloodlightContext and running the queue from where it's left off. The queue can be pulled from Controller.java, and truncated at after the remote dispatcher.
- "context-switching" would be handy for if our higher-tier module sends back out original message. This can happen when there is a bypass, or for some other reason. A check for it would be a Packet_in, since that's the only thing we'd ever send up. For now.
Flow of events:
client -> ClientChannelHandler + (us as [server])
|
V
switch -> OFChannelHandler -> controller -> !RemoteDispatchBase -> OFUStreamImpl -> [remote server] -> OFUstreamImpl -> OFDStreamImpl -> switch/client (us as [client])
|
+-----> [other internal modules] -> switch/client
(week 12)
DIMACS SDN workshop - realization that the basic architecture needs to be re-thought, starting again with the control plane messages. Time most spent on making posters, short writeup for IAB.
(week 13)
Reworked concept work for the control messaging. Subscriptions are in terms of events, process chain action, and subset of events. The subscription request from the server may be thought of as client configurations, in which the server configures the client to cater to its needs (and in turn, so that the client may receive its services.
Thought was also put into the notion of autoconfiguration, in which the controllers discover other controllers by themselves, as opposed to being preconfigured through a file. References for this process included UPnP, although this becomes potentially very complicated. Using broadcast as the default behavior also compromises a good bit of the initial design, as the hierarchy had used the point-to-point TCP connections in order to maintain context as messages were passed between controllers (albeit poorly).
(week 14)
An informal break due to holidays.
12/31 (week 15)
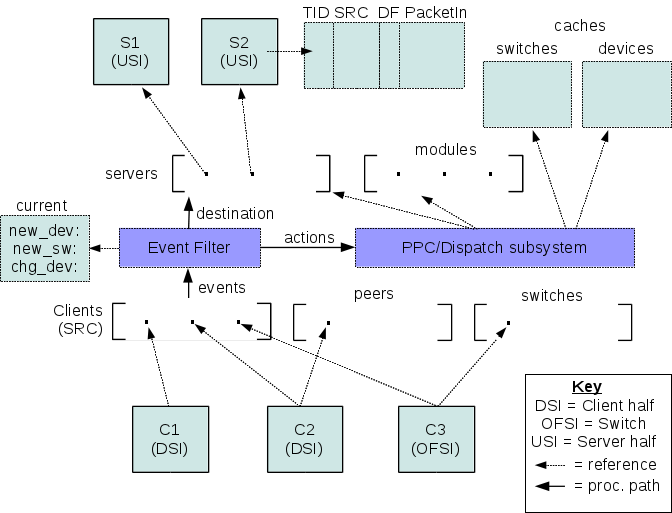
The architecture was revised yet again for what is hoped to be the final time. This includes:
- Filter system, to intercept events and present them in a specific manner to the dispatcher
- Caches, referenced by the dispatcher for cache-related filters. These are manipulated by the upstream objects when they receive results from their server halves.
- Flow entry caching - for storing results from servers. This system is "already there", as in, it is a matter of pointing things to the static flow pusher.
- Current events cache - for providing an event-triggered filter with the "current" context for the event. Manipulated by server results like the device/switch caches.
Each upstream object has a local table to map transactions to source, for proper choosing of return path.
The logical organization of the system then looks like this:

1/11 (week 17)
The weeks are going by faster, I swear. Need some ideas for demos. Focus should shift to describing this project in a top-down manner, e.g. how functionalities fit back into the architecture.
meeting scheduled Mon, 11am for details on the demo.
Things to do:
- think of method for sanity-checking forward dispatch
- control plane routing table - for allowing servers to determine if they can handle things on spot, or be client to higher-ups
- make use of CPLUpdate messages, their filters.
- tether each filter to a UID, 0 if
this(as in, a filter the server itself had asked for).- concept of a "localhost" (oi vay)
- Illustrate multi-service transaction : authentication + mobility path setup. (homebrew OpenRoads)
1/14
Meeting 1 of this week. Discussion of possible demos combining several services into one and the testbed topology for running said topology.
- two islands (admin domains, possibly - whose interconnection is an open logistics problem. One word: BGP) - and two layers of controllers. (demo horizontal interconnect, hierarchy)
- service reachability - not all can reach eachother directly (demo control forwarding)
- execution - two streaming hosts (client-server), with a mobile client. (demo usage in experimental setting)
- steps: authentication, resolution, stream setup, host mobility, readjustment of stream.
- traffic injection to data plane, active participation by controller (controller can send packets to end host, e.g. responses to resolution queries)
- using a testbed - NetFPGA cubes with switches and lower tier, nodes 1-11/12 as higher-tier controller(s).
The specifics of the execution of the demo mentioned above are:
- A client attaches and must authenticate with the network. The authentication result is stored locally at tier 1.
- This client is located in one admin domain, by default unable to communicate with admin domain 2, where the server lives.
- The client wishes to contact a stream server at a known address. It initiates a request, which triggers an address resolution.
- The address is resolved by a service that maintains a global map of hosts to addresses, tier 2. This implies some amount of transparency from one tier to another.
- The resolution maps a location to the client, injecting a flow that permits traffic to cross domain boundaries. A reply from the server does likewise.
- The client moves to the same domain as server. The injected flows are torn down by some mechanism. We can name a few, though being proactive is hard:
- by active trigger by host departure and arrival. This is completely reactive.
- flow timeout due to inactivity. This is a passive, autonomic approach.
- consistency check service. If a client appears in two distinct locations, remove all but the flows to the most recent location. This is also reactive.
1/15
Several points to rehash:
- There's only so many layers you want to add to the hierarchy, as it implies delay in service.
- In theory, we want any component to be able to escalate something.
- Listeners for switch join/leave events are probably looking for topology transparency. That implies that they also need FEATURE_REPLY and PORT_STAT messages, and that the DStream entity needs to maintain some sense of what is there. So, the DStream entity should have a way to track the switches that are below the client it represents, and a way to be passed as the correct switch to the modules looking for PacketIns.
- The switches themselves need to be able to alias write() with DStream's, so it has a way to recover the context of TID, and to send it back as a CPLMessage.
- So CPLSwitchImpl > OFSwitchImpl, and CPLDStream (re-name for relevance) as a shim with its own context for keeping track of TID (CONTEXT_TID).
- Tracking TID - hopefully possible through the context, though not under all cases to IOFSwitch.write(). A quick glance shows that as long as write() is called through receive(), the context can be preserved.
w/o 1/27-2/2
A mild hiatus during the week-long Juniper hackathon. On the meanwhile:
- reworked routing table + forwarding table for the control plane implementing a very simplified RIP/split horizon -like service info dissipation mechanism. Hop count is used as the preferred reachability mechanism, and is encoded in the CPLVendorData header.
- transparency mechanism for topology information. A higher-tier controller seeking switch info is assumed to be seeking topology transparency. This implies:
- transmission of all collected feature replies from the lower tiers (no two low-tier controllers connect to the same switch)
- escalation of topology data (PacketIn and PortStats, required by topology and link discovery modules)
- Need to work out the details of what is needed/not needed for a control plane to be deemed functional. Do we need all of the controllers properly running? Currently this is the case. However, if each controller is a separate functional component, technically not all components are equally critical to the core functions of a NOS.
w/o 2/3-2/9
It is not week 21 until I go to sleep and wake up the same day (2/10).
Not much change in architecture, but refactoring nevertheless. The system can be split into a few, relatively disjoint components:
- Logical connectivity: The channels and control plane topology abstraction. This includes loop prevention in the control plane, context maintenance, and general in-controller representation of its adjacencies and the control plane topology.
- Packet process chain: How packets a controller receives is handled and tracked across processing, escalation, and return. This involves using info generated and tracked by 1. in order to encapsulate/decapsulate control plane messages.
- Filters and actions: How the controller responds to control messages, and decides where packets it received goes. This is part of the dispatcher, which I kind of see as a event-driven scheduler.
- Application modules: The applications that leverage the first three to function. They live in the local process chain of 2.
w/o 2/24-3/2
2/28
Many revisions to things:
- update to Mininet 2.0.0
- update to topologizer
- first working example of peer proxy
Details as follows:
- Mininet update. Scripts break without it. This involves the rough following steps:
- removal of old mininet, openflow, and ovs source directories
- pull from mininet repo
- kill any ovs processes (ovs-db and vswitchd), unload kernel module
- manual restart of ovs once re-installed, if mininet complains about connection refusal (sometimes ovs runs, but not properly).
Mininet's syntax is a bit different in 2.0. starting a linear topology with 3 switches, to a remote controller becomes:
sudo mn --topo=linear,3 --controller=remote,ip=192.168.1.20
- Topologizer (makeshift script for launching multiple floodlights). Added ways to launch with terminals, no logging, backgrounded etc. Killing of processes.
- peer proxy: layer 1 of the control plane node, which supports route setup and routing to services, which includes peer forwarding of services. In addition:
- invisibility of peers to one another, since we don't want peers to ask each other for services they don't host. Peers do not show up in each others' route tables.
- service advertisement propagation, across to peers that don't see the service.
3/1
We re-visit and revise the event filter/dispatch subsystem. This is layer 3 in our control node.
- Event Types - the types of events we can receive from Floodlight's core system.
- switch - new, port change, removed
- message - various OpenFlow messages: we stick to Packet_In, Port_Stat, Vendor (custom messages), each a separate event
- device - new, removed, changed ( IP, VLAN, MOVED )
- all - everything above
- Filter Types - the fields of things to match an event on. Varies with the type of event. We want a stable basis, and let the remote services take care of the finer details. Off the top of the mind:
- switch - DPID, current event trigger switch
- device - MAC, current event trigger device, DPID of attachment
- Packet_Ins - certain device (or event trigger device), certain switch (event trigger switch) - by MAC and DPID, respective (we're narrowing our choices for sanity)
- Port_Status - ???
- Vendor - Vendor ID
- all - anything in that event
- Process chain operations, associated with each server (sID), after we send it off to our service provider:
- ALLOW - just a server telling us to carry on with local processing of the message. Don't write out, just return CONTINUE
- SPLIT - keep processing after sending up - write out and return CONTINUE
- DIVERT - stop processing the message, don't continue until the server answers - write out, save message context (indicate it had been DIVERTED so it can be resumed upon return), return STOP
- DENY - a server wanting us to just drop the message. Don't write out, return STOP.
These return consensus-driven CONTINUE or STOP commands if multiple servers are interested in one event type. In general, we want to be conservative - STOP-related ops like DIVERT take precedence over Continue-related ops like SPLIT. Basically all of these are ANDed together.
Dispatcher behavior algorithm.

w/o ¾-3/9
¾
Filter subsystem.
The syntax - This is heavily based on BPF, as in there are a handful of base elements - packet fields, and operations and and or. In terms of operation, it is something else. The properties are:
- Each component is a 4-tuple: event type, directionality, attribute, and value. We can AND or OR these together to form the rules.
Event Types Network events that can be detected via the control channel, ANY Directionality SRC, DST, or ANY Attribute DPID, VLAN, IP, MAC, ANY Value for Attributes, in order - long, short, int, long, none
ANY is a wildcard, with the most lenient rule being "ANY event, ANY attribute, ANY value"
- Some components can be condensed into one (a rule) - these are usually multiple rules ANDed together, e.g. "src IP A AND dst IP B".
- "rules" are a condensation of one or more components.
- Each rule is tied to a service ID, and as a result, a next-hop UID.
The matching occurs in the dispatcher, and returns a set of service IDs and next-hop UIDs.
w/o 3/10-3/15
Route setup/capabilities advertisement.
Controllers inform one another of the services that they provide to the control plane. This information is conveyed in the form of a unique service ID (SID) and a series of network events of interest to the service, which should be forwarded to the service in order for them to be properly handled. Control plane service sets are learned by controllers via messages exchanged and propagated across the hierarchy. We construct a message propagation mechanism beginning with the following assumptions:
- since no tier serves a tier above, advertisements only need to move downwards, from high to low tiers.
- control planes remain small and topologically restricted compared to the data plane.
- peers do not serve one another e.g. disregard one another's services, as they provide identicalfunctionalities. Therefore advertisements are disregarded among peers.
While the hierarchy restricts the flow of message propagation, measures must be taken to prevent loops, notably within the bidirectional horizontal connections. In addition, multiple routes to a server may exist in the control plane, in which case we wish to choose a shortest path. We employ a message propagation mechanism and path selection mechanism similar to RIP with split horizon:
if message received
extract hop count, SID
if SID has already been seen
if this hop count < old hop count
discard old next hop
else
if message is from peer
discard message
else
record SID and next hop
for each known adjacency
if not sender of message
send to adjacency
the first block is the path selection stage, and the second, the forwarding stage. Paths are selected based on hop count, as a simple metric that is meaningful in networks whose links have approximately equal throughput.
Forwarding table/filtration subsystem.
The filter system (forwarding table) pulls up subscribers when events are dispatched. Subscribers are returned by their service IDs, which allows for remapping of Service IDs to next hop, the latter whose mapping to SID is maintained in the route table. This allows for tracking of bot best next hop and event-to-SID mapping despite possibilities of changes in next hop.
The syntax of the filter is simple, only functioning on matching against six items:
- DPID : as a hex string beginning with '0x'
- VLAN : a integral value
- Source/destination Hardware address : six colon-separated hex values '00:00:ab:cd:ef:90'
- Source/destination IP address : dotted-decimal integers 'x.x.x.x'
- event trigger item : event type.
Event trigger item refers to the cause of a certain event, e.g. a network host that triggered a new device event. So far, the first five are implemented. The last is a dilemma, as it can become a choke point in concurrency when event triggers are updated or checked frequently.
Items are described as source, destination, or any. source or destination only apply to network and hardware addresses and these specifiers are ignored for DPID and VLAN. 'any' is a wildcard that matches on either source or destination, and is a default for DPID and VLAN.
In addition to sending the event to a next hop to the service ID, a packet process chain action (PPC) is applied to the manner in which the controller behaves. This component is essentially firewall-like, however with four operations:
- ALLOW : process packet as normal
- DENY : send back a drop message, blocking the packet
- SPLIT : send copy of the packet upstream to SID, at the same time allowing process of message locally
- DIVERT : send copy upstream, however cease processing locally until results are returned.
When two service IDs for the same event return a different PPC, the PPCs are consolidated with this precedence order:
allow < [deny|split] < divert
with deny and split being combined into a divert action. This choice for precedence and priority handling is acceptable as long as we stand by the assumption that no two servers provide overlapping rules. For example, no service will absolutely rely upon a event being ALLOWed when another service relies on DIVERTing it, in which case, conflicts in handling will result in control plane malfunction.
w/o 3/31-4/1
Topic: Some thoughts about the role of core controller components, versus modules.
A controller in context of the current states of things, divides the control plane (or what was considered the control plane early on) into an application layer, and the system underlying it. The latter has become what is referred to as the control plane in the recent models of network operating systems. From a functional perspective, it appears as if the applications preform the computations specific to the behaviors imposed on the data plane, leaving the control plane to provide underlying functions such as network view abstraction and event scheduling and dispatch. (TODO to look up the formal delegations for these layers)
Using this idea as a basis, we can roughly guess at what functions belong where, and importantly, the breadth of functions to provide certain controller sub-components. What this leads to is that the core of a controller - the implementation of the control plane - probably does not generate control messages intended to modify the flow tables of the datapaths. This is a role left to the application layer, which among other things implements the network algorithms that manipulate the handling of traffic.
The exercise here ties back into implementation. The current controller core does not respond to PacketIns directly, but merely dispatches them to available modules (applications). The added message diversion function may be implemented in two ways, at first glance:
- By halting the processing of the message by further modules
- Writing a drop message back (buffer set to -1)to the switch prompting instruction, then halting the processing
The former does not prevent a datapath from sending further PacketIns to the same event, while the latter does. While the latter is cleaner in handling, and prevents unnecessary handling of multiple copies of PacketIns, it blurs the boundaries between application and control. A similar story holds for the return handling of a message processed by a remote server. Further processing of a response can be done at the client, but the extent of actions that the control plane can take are limited by the logical separation into two layers.
Maybe keeping this in mind will make fleshing out and tuning the implementation into less of a pain…
w/o 4/7-4/13
Process chain tracking, priorities, and contexts.
When we consider that several services may actually need ordering for the stack to operate property, we start thinking of execution priorities and process chain handling amongst the server uplinks. To get this working, we add two more contexts - a server priority (sort of like preorder/postorder processing of modules) and server process directives, similar to Floodlight Commands. Process directives are ultimately translated to Commands, so they are more or less the same. Directives, however, are tied to message processing behavior beyond that of a Command, since a message's standard Floodlight context does not survive past escalation, but directives do. A directive may be recovered after a message's return, or be re-interpreted as a return command to be applied to the return path.
w/o 4/14-4/20
Testing with a preliminary example:
- tier 1: proxy
- tier 2: forwarding, authentication
Processing conflicts will arise if forwarding functions are executed before authentication. This type of conflict cannot be resolved by simply juggling around tiers, since tier 1 will still receive both forwarding table rules from the respective services. So we assign a higher priority to authentication so that it is checked first.
w/o 4/21-4/27
A mild hiatus from usual work. Worked out a base set of slides potentially useful as part of my defense.
However, some insightful points, possibly:
- Check out threading and delegation of threads in Floodlight per switch. There may be a bottleneck in regards to scaling, according to an ONOS dev (Pankaj).
- Time measurements - If using PacketIns and PacketOuts, throw the timestamp into the payload right after packet construction, to bypass the overhead from the packet e.g. lingering in the network stack buffers, allowing better measurement of message processing overhead.
- A very good (big) concern that needs to be addresses is that of switch abstraction in higher tiers. As of now, we count on services being delegated in a way such that the higher tiers do not need any information about the topology. This may not always be the case if we eventually want tiering in terms of scope of network view.
For the last concern, we may be able to abuse the Topology objects supported in Floodlight. More code reading may be necessary to determine if this is true.
Switch performance testing is difficult. There is OVS, which may be possible to hack up a bit so we can pull times from it, but for anything else, this is not really feasible.
w/o 4/28-5/4
Tiered routing/resolution.
We can take advantage of the tiered structure of the control plane to tweak how a given controller "sees" the network. The view of higher tier nodes may be simplified into domains, or clusters of switches connected to an adjacent client node. Resolution based on this mapping can rely on higher tiers to give a general location of a host, then rely on lower tiers to pinpoint exact attachment points.
This implies client-server coordination specifically tuned to this service, and not just the generic schedule/dispatch mechanism. A list of first-guess functions needed are:
Client node (modified ForwardingBase)
- mapping of hosts and domains to attachment point - former is external ports, latter, internal
- ability to pull routes using both results of queries to server tier and regular attachment points
- flow installation along switches.
Server node
- maintain domain-host mappings
- return attachment point map of destination nodes.
A client may have the following flow of operation:
if packetIn from a new host
escalate
processResponse:
if dest local
find route to attachment point
if dest remote
find attachment of domain
find route to domain atachment point
else
bcast
The server just derives the destination's attachment point in terms of domain, and replies with a PacketOut. Domains, to keep it simple, will have an identifier that can be aliased to an attachment point as describable in a PacketOut.
Attachments (2)
- module_arch.png (85.4 KB ) - added by 14 years ago.
- controller_arch_rev-3.png (62.4 KB ) - added by 14 years ago.
{kind=link}
{kind=link}
Download all attachments as: .zip